
What is Kafka?
Kafka is a distributed messaging streaming platform that is used to publish and subscribe to stream the records that can handle a high volume of data and enables you to pass messages from one end-point to another.
For example, We have one entity data(DB) and it is centralized for the entire system. Now in case, this entity crashed, the whole system crashed and we lost the entity data.
Centralized Data
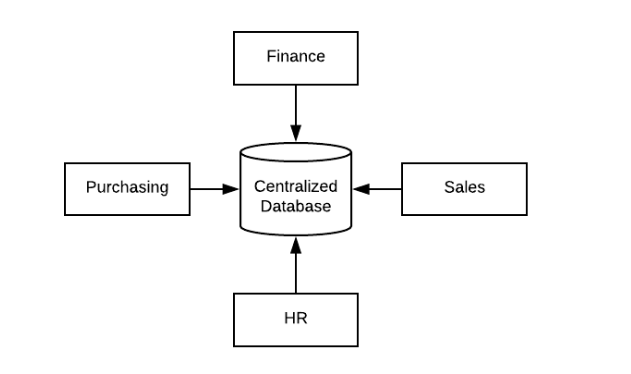
Distributed Data
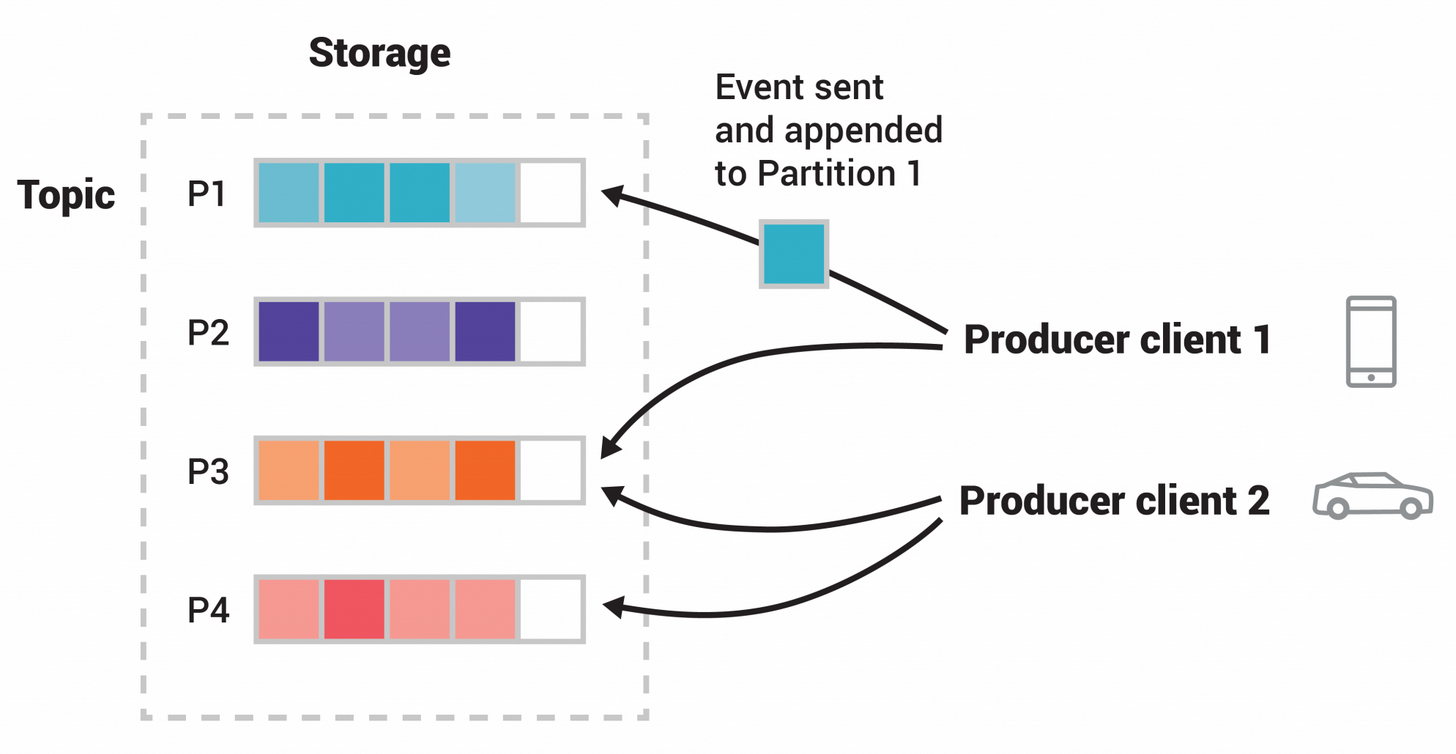
This example topic has four partitions P1–P4. Two different producer clients are publishing, independently from each other, new events on the topic by writing events over the network to the topic’s partitions. Events or Partition’s Data with the same key (denoted by their color in the figure) are written to the same partition. Note that both producers can write to the same partition if appropriate.
To make your data fault-tolerant and highly available, every topic can be replicated, even across geo-regions or data centers, so that there are always multiple brokers that have a copy of the data just in case something goes wrong, you want to do maintenance on the brokers, and so on. A standard production setting is a replication factor of 3, i.e., there will always be three copies of your data. This replication is performed at the level of topic-partitions.
Why is Apache Kafka better than other event streaming platforms?
Other message brokers like Java Messaging Service (JMS), Apache ActiveMQ, RabbitMQ, and others have been effective at transferring data. However, they are not designed to handle large amounts of data and provide fault tolerance.
Apache Kafka is designed to handle large volumes of messages with log(metadata) and provide fault tolerance through replicas(data clones). It can be used as the central nervous system of a distributed architecture that delivers data to multiple systems and it’s extremely fast because it decouples(through partitions) data streams.
Benefits of Using Apache Kafka
- Apache Kafka is capable of handling millions of data or messages per second.
- Apache Kafka Works as a mediator between the source system and the target system. Thus, the source system(producer) data is sent to Apache Kafka, where it decouples the data, and the target system(consumer) consumes the data from Kafka.
- Apache Kafka supports high-volume data delivery because it subdivides the events into small batches to reduce network calls. It compresses data and sends it to a server that writes them in a compressed form.
- Apache Kafka temporarily stores received messages allowing consumers to access them long after reading and responding.
- Apache Kafka can maintain fault tolerance. Fault-tolerance means that sometimes a consumer successfully consumes the message that the producer delivered. But, the consumer fails to process the message back due to backend database failure, or due to the presence of a bug in the consumer code. In such a situation, the consumer is unable to consume the message again. Consequently, Apache Kafka has resolved the problem by reprocessing the data.
Drawbacks of Apache Kafka
- Complexity: One of the major disadvantages of Kafka is its complexity. Kafka is a distributed system that consists of multiple components such as brokers, producers, consumers, and Zookeeper. These components work together to ensure high availability, fault tolerance, and scalability. However, this also makes Kafka more complex than traditional messaging systems.
- Operational Overhead: Kafka requires operational overhead to maintain and manage the system. This includes configuring the brokers, monitoring performance, managing replication, and ensuring data consistency.
- Dependency on Zookeeper: Managing a Zookeeper cluster adds another layer of complexity and overhead to the overall system.
User Cases of Apache Kafka
Here is a description of a few of the popular use cases for Apache Kafka.
- Messaging: Kafka works well as a replacement for a more traditional message broker. Message brokers are used for a variety of reasons (to decouple processing from data producers, to buffer unprocessed messages, etc.). In comparison to most messaging systems, Kafka has better throughput, built-in partitioning, replication, and fault-tolerance which makes it a good solution for large-scale message processing applications.
- Website Activity Tracking: The original use case for Kafka was to be able to rebuild a user activity tracking pipeline as a set of real-time publish-subscribe feeds. This means site activity (page views, searches, or other actions users may take) is published to central topics with one topic per activity type.
- Streaming Process: Kafka processes data in processing pipelines consisting of multiple stages, where raw input data is consumed from Kafka topics and then aggregated, enriched, or otherwise transformed into new topics for further consumption or follow-up processing.
Apache Kafka’s Architecture
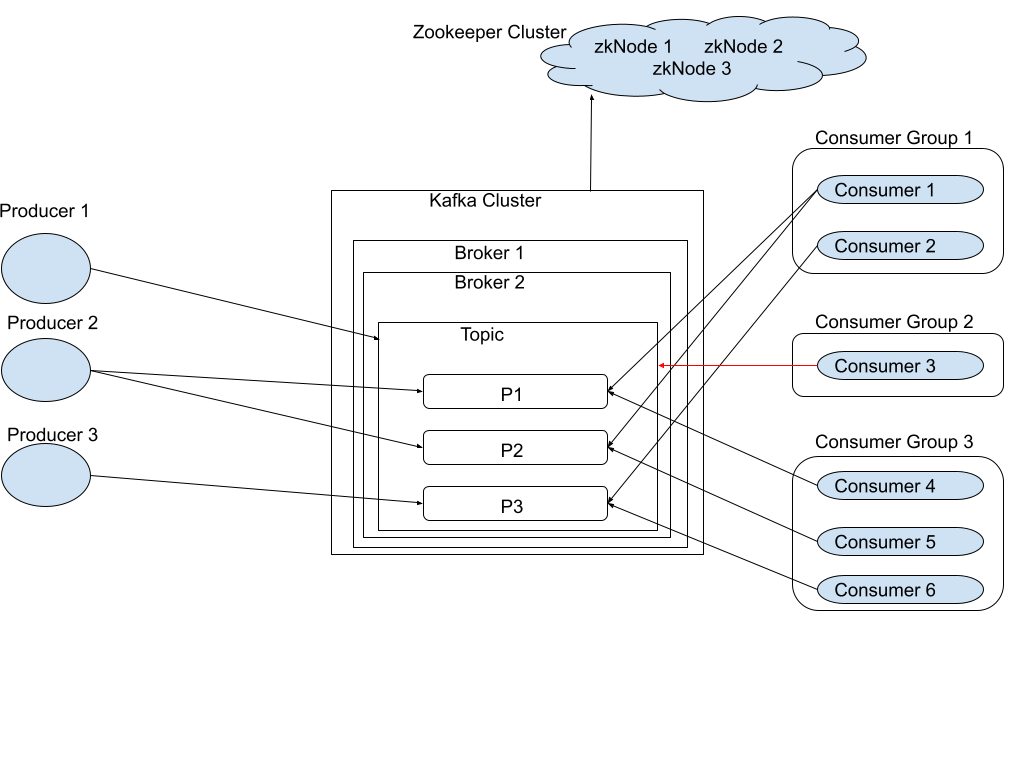
- Topics: A topic is similar to a table/folder in a database/file system, and the events are the data/files in that table/folder. An example topic name could be “employee”.
- Topics in Kafka are always multi-producer and multi-subscriber: a topic can have zero, one, or many producers that write events to it, as well as zero, one, or many consumers that subscribe to these events.
- In Kafka, the Topic unique ID is a NAME. we can not create the same name topics in a cluster. Topics are split into multiple partitions.
- All the messages/events within a partition are ordered and immutable.
- Each message/event within a partition has a unique ID associated known as Offset.
- Event: An event is also called a message or record.
- Replicas: In Kafka, Replicas means the backup of a partition and storing it to other brokers. Kafka makes a copy of the partition and stores it to the other broker so that data can never be lost in a data-fault.
- Replicas are not used directly by producers or consumers. It is used just in case things go wrong with the data.
- In short, Replicas are used to prevent data loss(fault-tolerant).
- Partition: Partition, meaning a topic is spread over some “buckets” located on different Kafka brokers.
- A partition contains a subset of the messages written to a topic. New messages are appended to the partition, guaranteeing that messages maintain their order at the partition level.
- If you have multiple partitions and when one partition goes down, you can still read from another partition(replication).
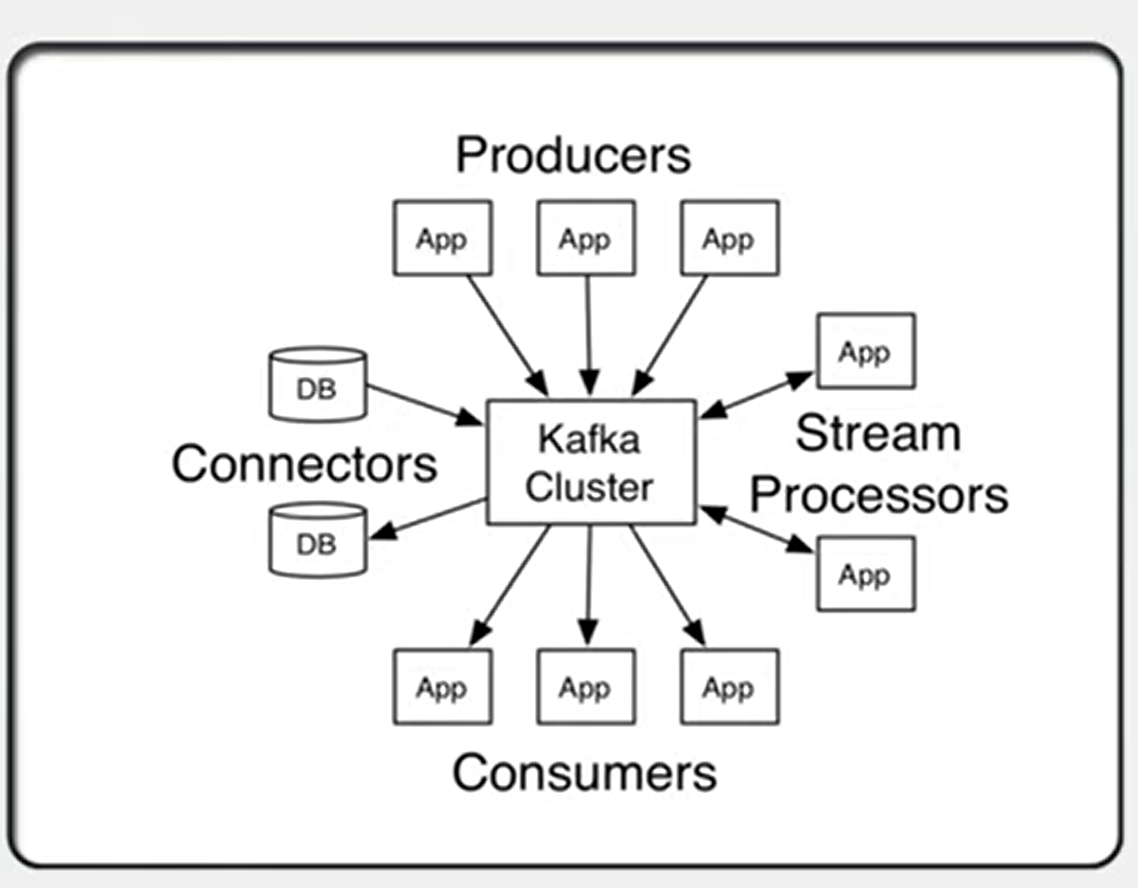
- Producers: Producers are those client applications that publish(write) events to Kafka.
- Producers can produce the data on the partition level as well as the topic level.
- When the producer sends data to topics it means to send data to partition indirectly in a round robin system. This is a default configuration is available in Kafka.
- If we want round-robin behavior, just do not pass the key when writing to Producer and DefaultPartitioner will do the job for us. We do not need to write a custom implementation.
- Following are some default partitioning strategies:
- If a partition is specified in the record, use it
- If no partition is specified but a key is present choose a partition based on a hash of the key
- If no partition or key is present choose a partition in a round-robin system.
- Producers are applications that write/publish data to the topics within a cluster using the producing API.
- Consumers: Consumers are those who subscribe to (read and process) these events.
- Consumers can consume/read data from the topic level or specific partition of the topic within a cluster using consuming API.
- Consumers are always associated with exactly one consumer group.
- Brokers: Brokers are simple software processes that maintain and manage the published messages. Brokers are also known as Kafka servers.
- Brokers also manage the consumer offsets and are responsible for the delivery of messages to the right consumers.
- A Set of brokers who communicate with each other to perform the management and maintenance tasks are collectively known as a Kafka Cluster.
- We can add more brokers in an already-running Kafka cluster without any downtime.
APIs provided by Apache Kafka
Apache Kafka provides Core APIs like Producer APIa, Consumer APIs, Streams APIs, Connector APIs, and Admin APIs.
Conclusion
Kafka is a better choice for enterprises. Kafka Streams are easy to understand and implement for developers of all capabilities and have truthfully revolutionized all streaming platforms and real-world data feeds.


